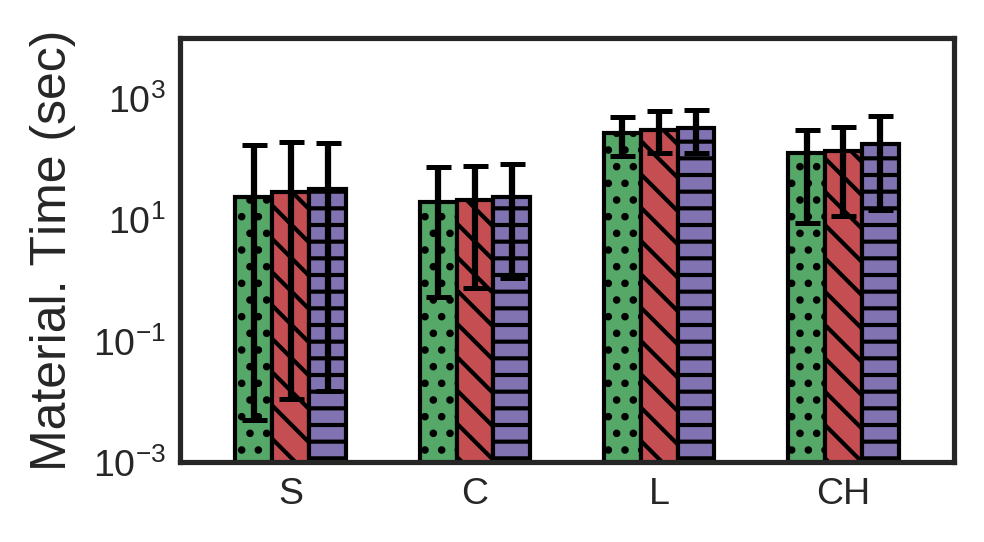
We ran our experiments on a server with 128 vCPU cores at 2.5GHz, 64KB L1 cache, 512KB L2 cache and 8192KB L3 cache
each, and 2TB RAM. We use 128 nodes on the same server with resources split up evenly between them.
for data and queries for tests. We use groups
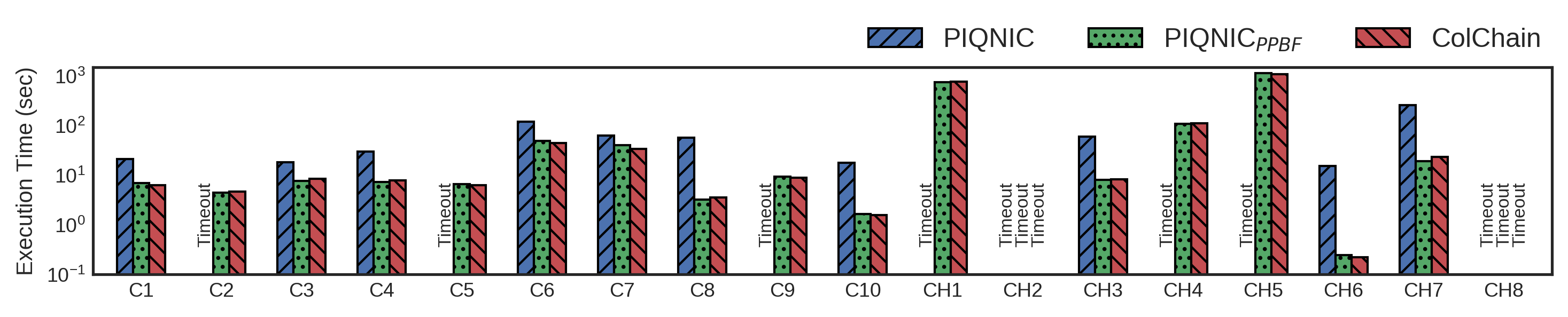
Query Execution Time (QET) in milliseconds for group S over different systems (log scale)
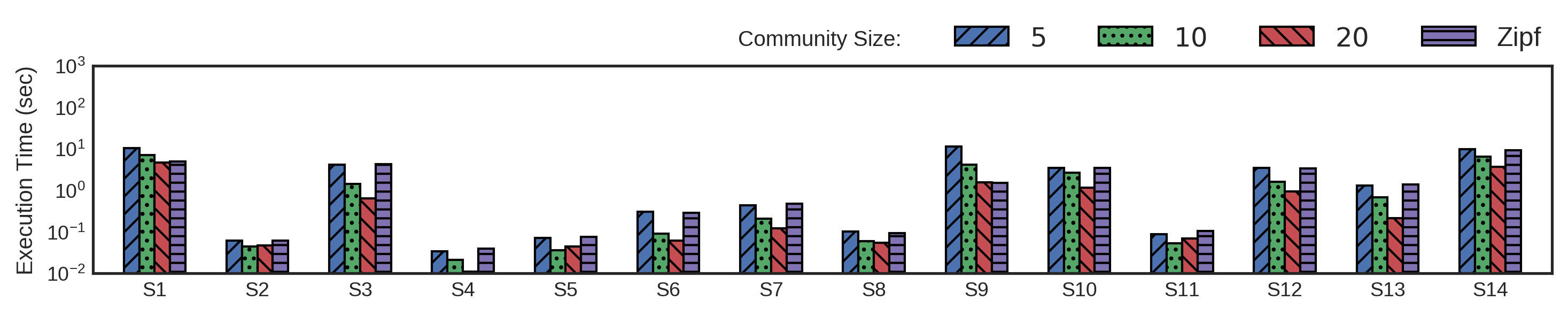
Query Execution Time (QET) in milliseconds for group S over different community sizes (log scale)
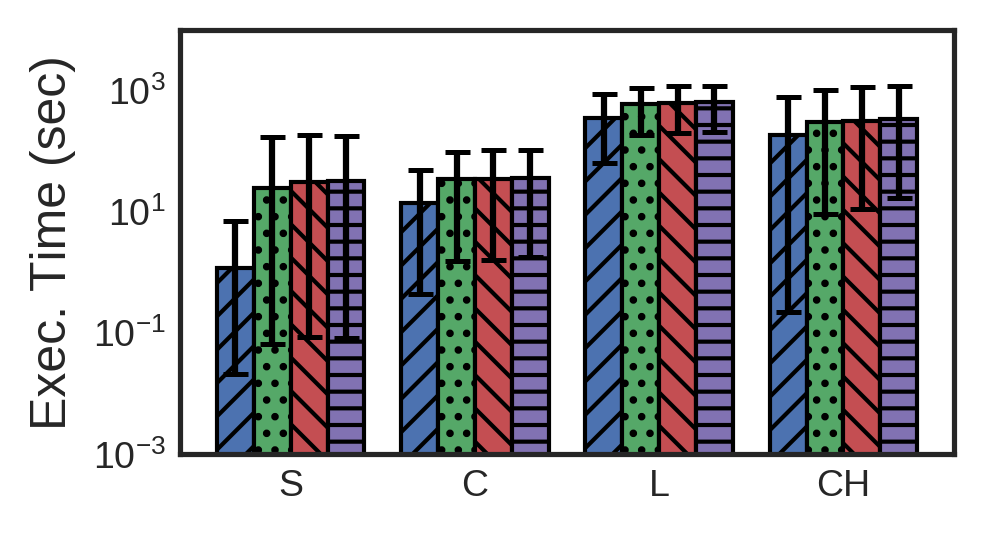
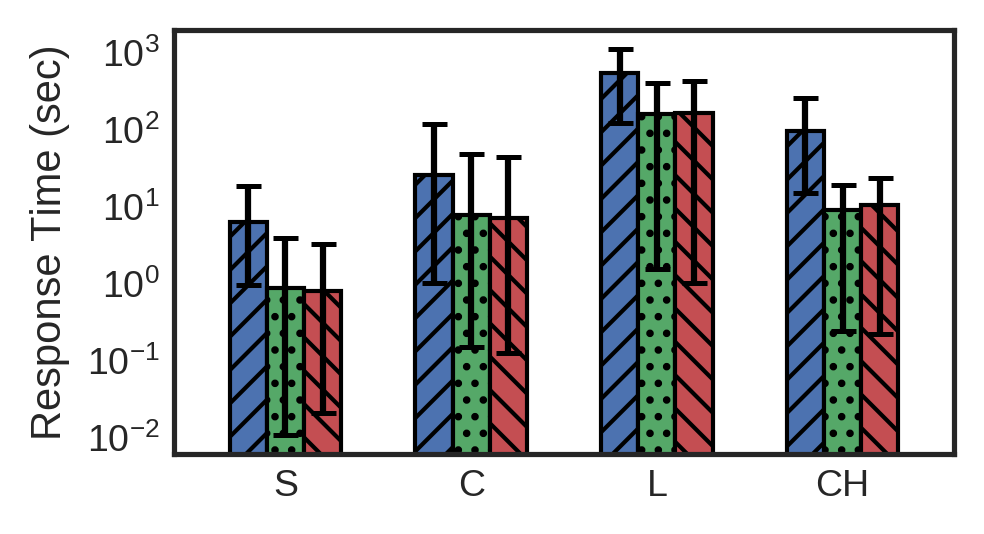
Query Response Time (QRT) in milliseconds for all query groups over different systems (log scale)

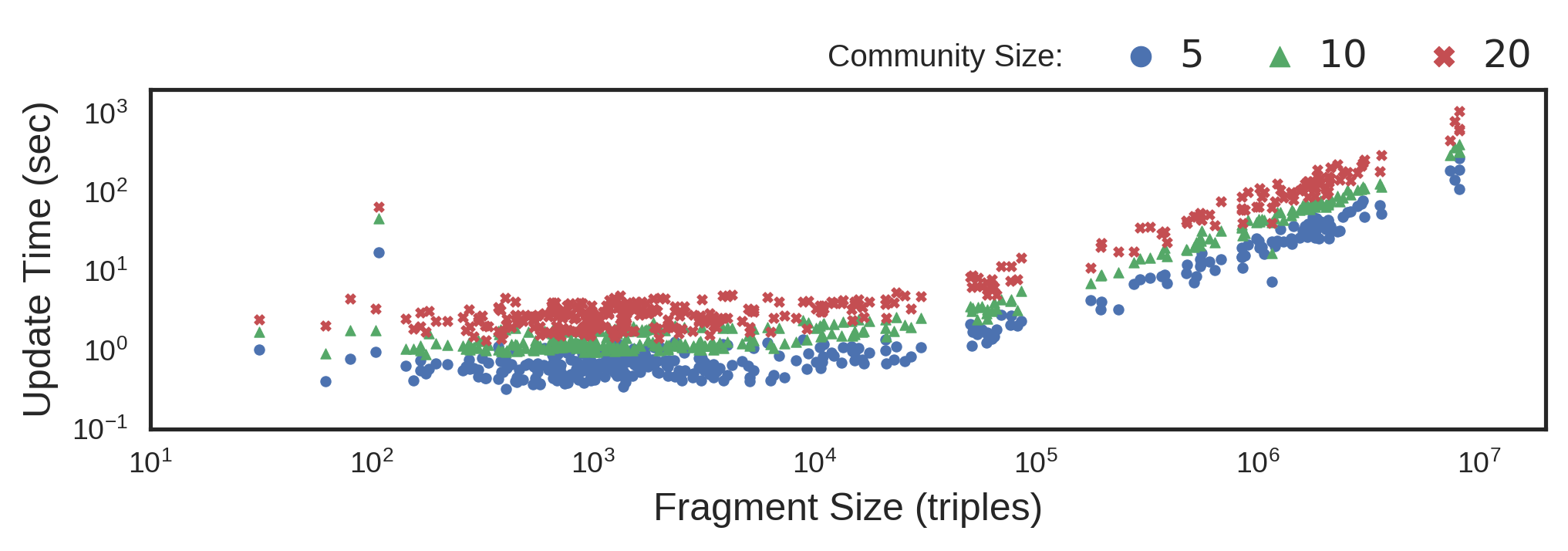
Update Overhead Time (UOT) in milliseconds for varying community sizes over different sized updates updates (log scale)