In Proceedings of the VLDB Endowment 2021, Vol. 14, No. 13 ISSN 2150-8097.
(PDF),
Publisher Link
Abstact
Over the past few years, we have witnessed the emergence of large knowledge graphs built by extracting and combining information from multiple sources. This has propelled many advances in query processing over knowledge graphs, however the aspect of providing provenance explanations for query results has so far been mostly neglected. We therefore propose a novel method, SPARQLprov, based on query rewriting, to compute how-provenance polynomials for SPARQL queries over knowledge graphs. Contrary to existing works, SPARQLprov is system-agnostic and can be applied to standard and already deployed SPARQL engines without the need of customized extensions. We rely on spm-semirings to compute polynomial annotations that respect the property of commutation with homomorphisms on monotonic and non-monotonic SPARQL queries without aggregate functions. Our evaluation on real and synthetic data shows that SPARQLprov over standard engines incurs an acceptable runtime overhead w.r.t. the original query, competing with state-of-the-art solutions for how-provenance computation.
Cite
Hernández, Daniel, Luis Galárraga, and Katja Hose. "Computing how-provenance for SPARQL queries via query rewriting." Proceedings of the VLDB Endowment 14.13 (2021): 3389-3401.
EXPERIMENTS
Benchmarks and Competitors
We evaluated the viability of SPARQLprov to compute
provenance for SPARQL query answers by measuring the runtime
overhead incurred by the rewritten query w.r.t. the original
query on two standard RDF/SPARQL engines, namely Virtuoso and
Fuseki. Our evaluation consisted of several experiments, including
a comparison with GProM and TripleProv, two state-of-the-art solutions
to compute how-provenance for queries. Our experimental benchmarks comprise:
WatDiv: A state-of-the-art benchmark for SPARQL queries.
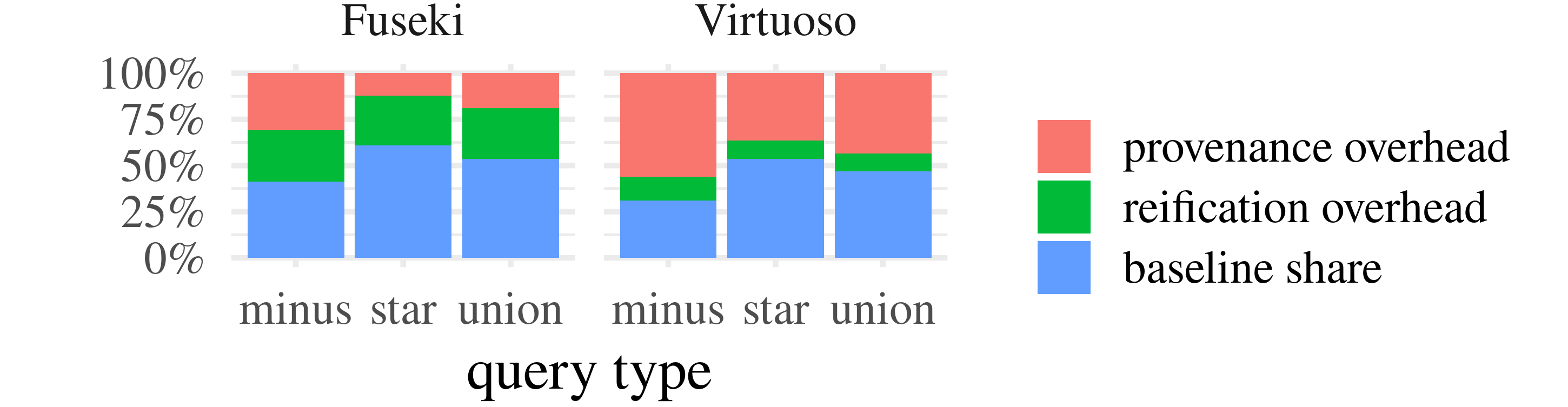
We use it to compare SPARQLprov to the competitors, as well as to evaluate the impact of the reification scheme on the overall runtime.
TPC-H: To evaluate
the scalability of SPARQLprov as the amount of
data increases, we used this benchmark to
generate datasets of different sizes.
Wikidata: We used this dataset to evaluate the runtime overhead of
SPARQLprov on a real-world
dataset.
Experiments
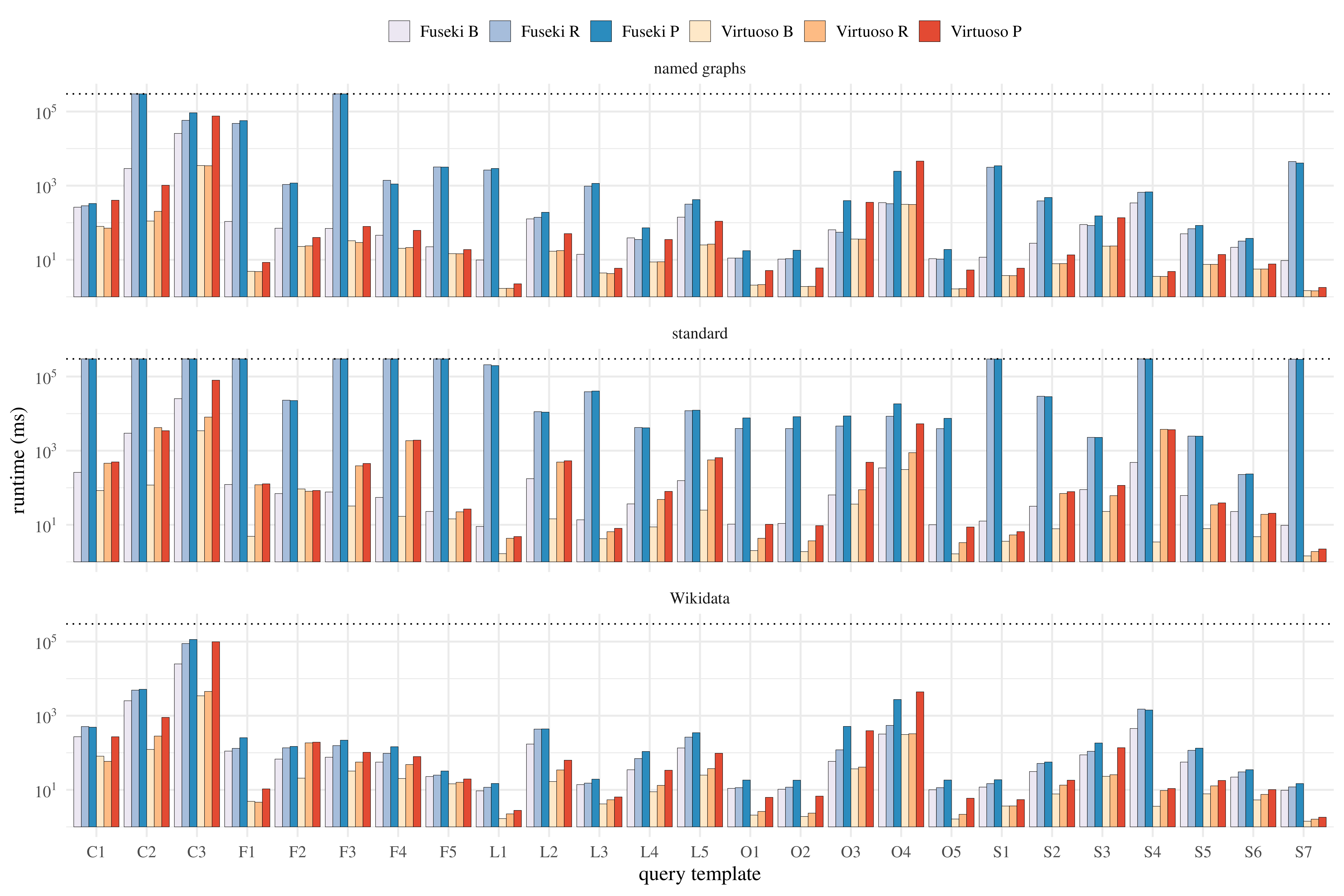
Impact of reification: We evaluated SPARQLprov's runtime overhead on data encoded with three reification schemes, namely
named graphs, the standard reification, and the Wikidata reification. This evaluation was conducted on the WatDiv benchmark.
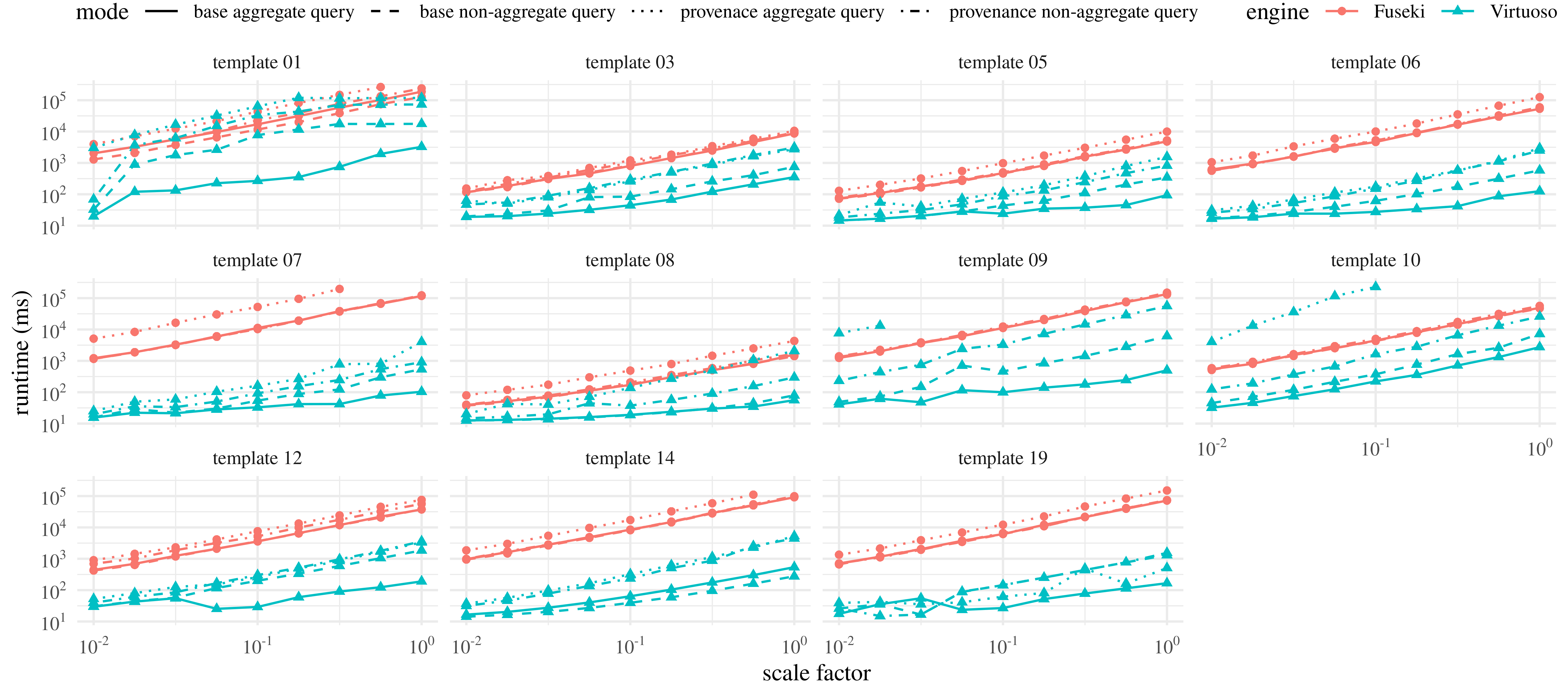
Scalability evaluation: We studied the scalability of SPARQLprov using the TPC-H benchmark that we used to generate
8 synthetic datasets of increasing size.
Real data: We evaluated SPARQLprov on Wikidata, a real-world RDF knowledge graph.
Comparison with other systems: We compared SPARQLprov on the Watdiv benchmark against other solutions for how-provenance, namely TripleProv and GProM.
System Settings
All the queries were executed in a machine with an AMD EPYC
7281 16-Core Processor, 256GB of RAM, and an 8 TB HDD
disk. We use Virtuoso (v.~7.2.5.1) and Fuseki (v.~3.17.0
with TDB1 as storage driver) to test our approach. More details
about the experimental settings can be found in our
reproducibility archive.
For each experiment, we run all queries once to warm up the
engine and then, we run each query load 5 times. For each
query, we report the average response time of the
executions.
Experimental results
In our experiments, we compared our approach (with Virtuoso and Fuseki as backends) against the two state-of-the-art approaches TripleProv and GProM.
We added an additional 5 non-monotonic queries (O1-O5) involving OPTIONAL. The list of queries is avaible under Downloads at the end of this page.
Figure: Watdiv query execution times per reification scheme and query template. The top dotted line represents the timeout.
B: base query, R: reified query, P: provenance query.
Figure:
TPC-H execution times per query template.
Figure:
Wikidata time overhead.
Figure:
Watdiv query execution times per engine and query template. For our approach (denoted as Virtuoso) we report the results obtained with named graphs reification scheme, and for GProM the results obtained with the vertical partition scheme. The top dotted line represents the timeout.
Source Code
The source code of SPARQLprov as well as the utilities to reproduce results of our experiments can be found
in our reproducibility archive.
Datasets and Queries
WatDiv: This benchmark uses a syntetic
dataset described in
the official
WatDiv benchmark website. We used the
100
million triples dataset for our experiments. Here are other potentially interesting downloads:
TPC-H: This benchmark uses a syntetic
dataset. The tool to create the dataset is available in the
official TPC-H benchmark
website. This tool generates tables codified as tab-separated values.
Our reproducibility scripts take care of translating
these data into RDF.
Wikidata: We used the
Wikidata dump from January 27, 2020 from Wikimedia
foundation. We have created a
stable copy of
the dataset for long-term preservation concerns.