Size and characteristics of the datasets
Kashif Rabbani, Matteo Lissandrini, and Katja Hose.
In Proceedings of the Very Large Databases 2023 (Volume 16 Issue 5, VLDB-2023 ) August
2023, Vancouver Canada.
Publisher Link:
https://www.vldb.org/pvldb/vol16/p1023-rabbani.pdf
Read extended version
Kashif Rabbani, Matteo Lissandrini, and Katja Hose.
In Proceedings of the 2023 International Conference on Management of Data,
(SIGMOD-Companion '23)
June 18-23, 2023, Seattle, WA, USA.
Publisher Link: acm/doi/10.1145/3555041.3589723
Visit Demo Website
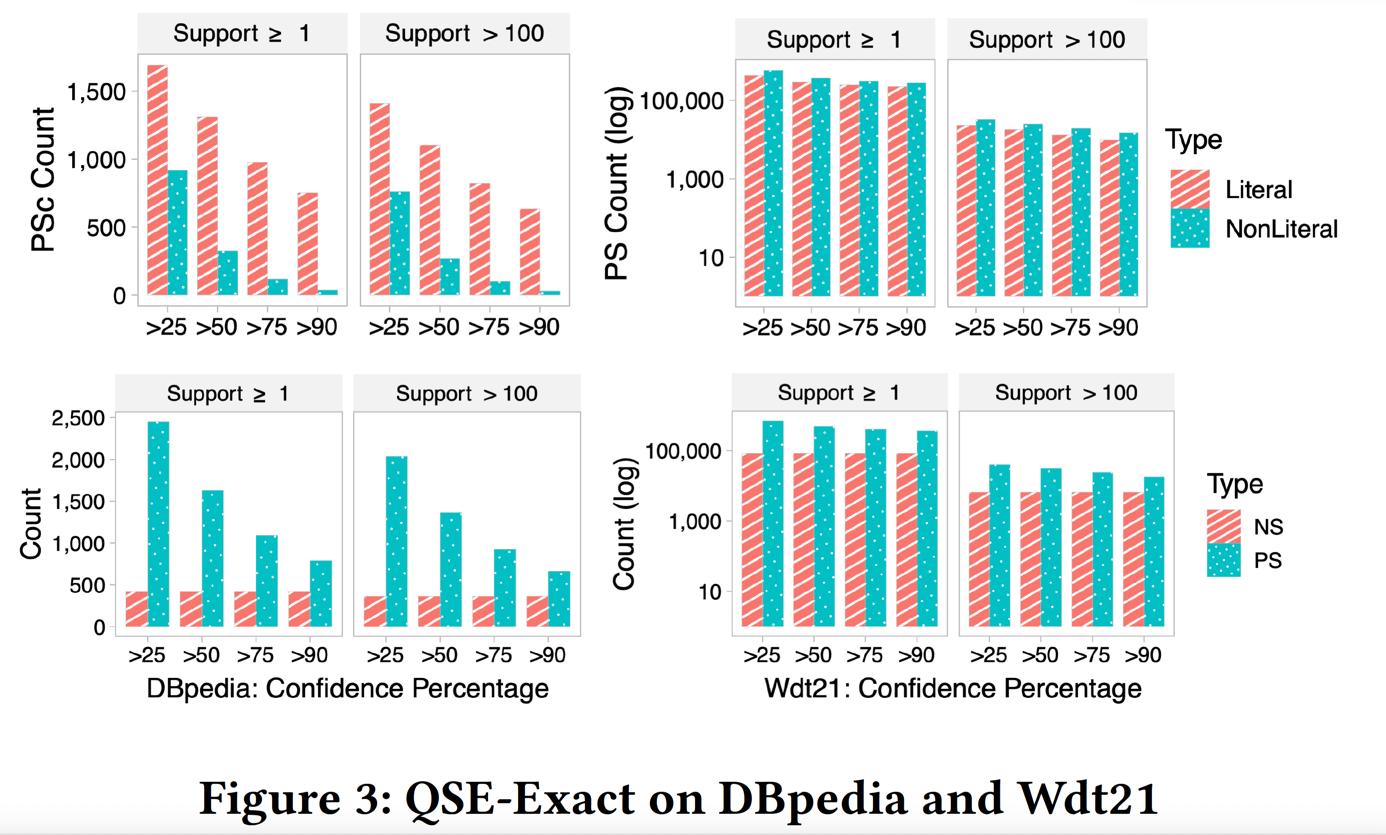
Knowledge Graphs (KGs) represent heterogeneous domain knowledge on the Web and within organizations. There exist shapes constraint languages to define validating shapes to ensure the quality of the data in KGs. Existing techniques to extract validating shapes often fail to extract complete shapes, are not scalable, and are prone to produce spurious shapes. To address these shortcomings, we propose the Quality Shapes Extraction (QSE) approach to extract validating shapes in very large graphs, for which we devise both an exact and an approximate solution. QSE provides information about the reliability of shape constraints by computing their confidence and support within a KG and in doing so allows to identify shapes that are most informative and less likely to be affected by incomplete or incorrect data. To the best of our knowledge, QSE is the first approach to extract a complete set of validating shapes from WikiData. Moreover, QSE provides a 12x reduction in extraction time compared to existing approaches, while managing to filter out up to 93% of the invalid and spurious shapes, resulting in a reduction of up to 2 orders of magnitude in the number of constraints presented to the user, e.g., from 11,916 to 809 on DBpedia.
Rabbani, Kashif; Lissandrini, Matteo; and Hose, Katja. Extraction of Validating Shapes from very large Knowledge Graphs In Proceedings of the Very Large Databases 2023 (Volume 16), August 28 - Sept 02, 2023, Vancouver, Canada.
We have used the following datasets:
You can download a copy of these datasets from our single archive.
To evaluate the performance of our approach, we used QSE with the above-mentioned datasets on a single
machine with Ubuntu 18.04, having 16 cores, 1TB HDD and 256GB
RAM and measured the execution time.
We have the following metrics to evaluate our approach against others:
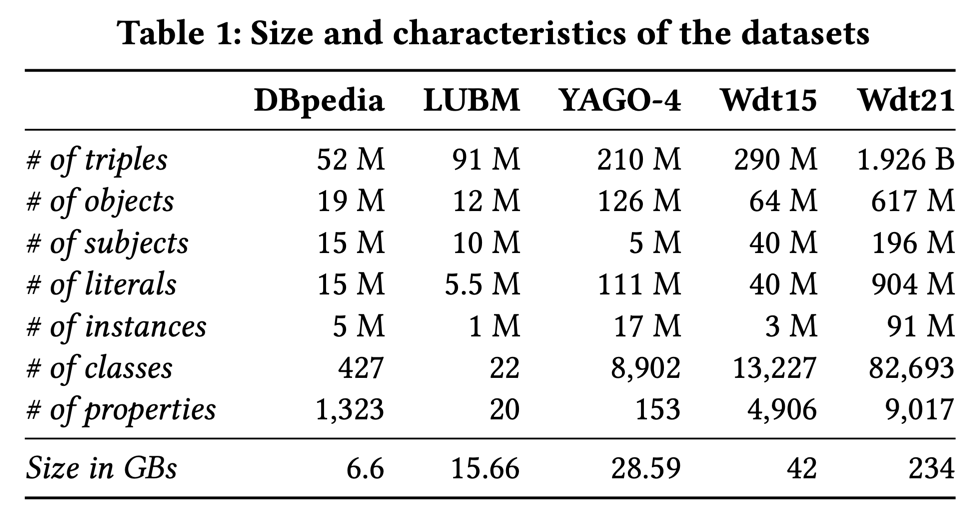
Size and characteristics of the datasets
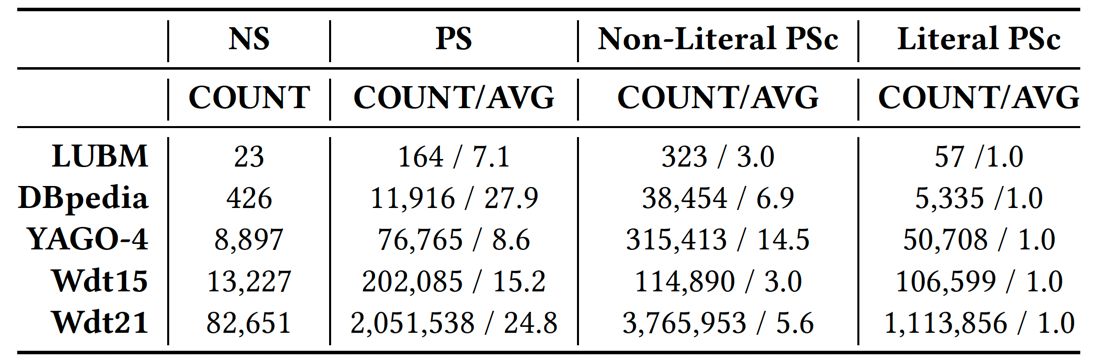
Shapes Statistics such as Node Shapes (NS), Property Shapes (PS), Property Shapes Constraint (PSc)
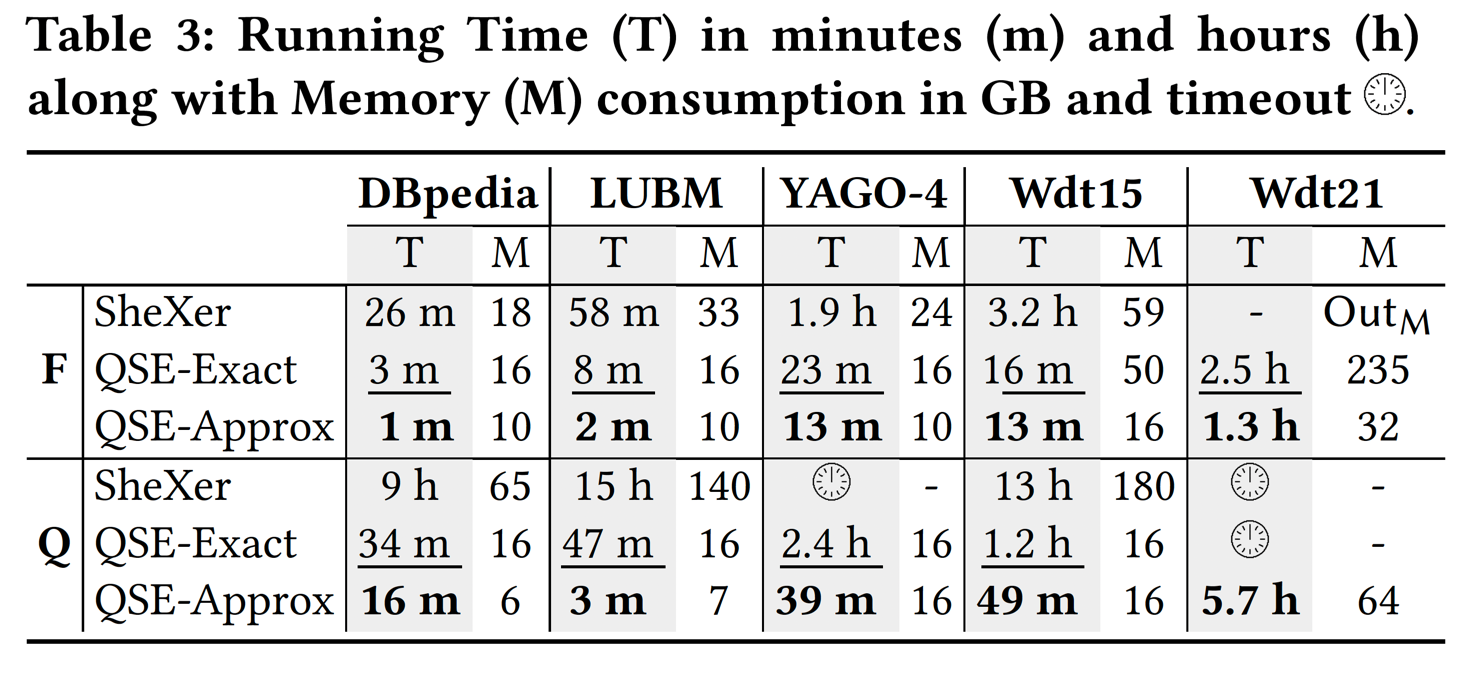
Running Time and Memory Consumption
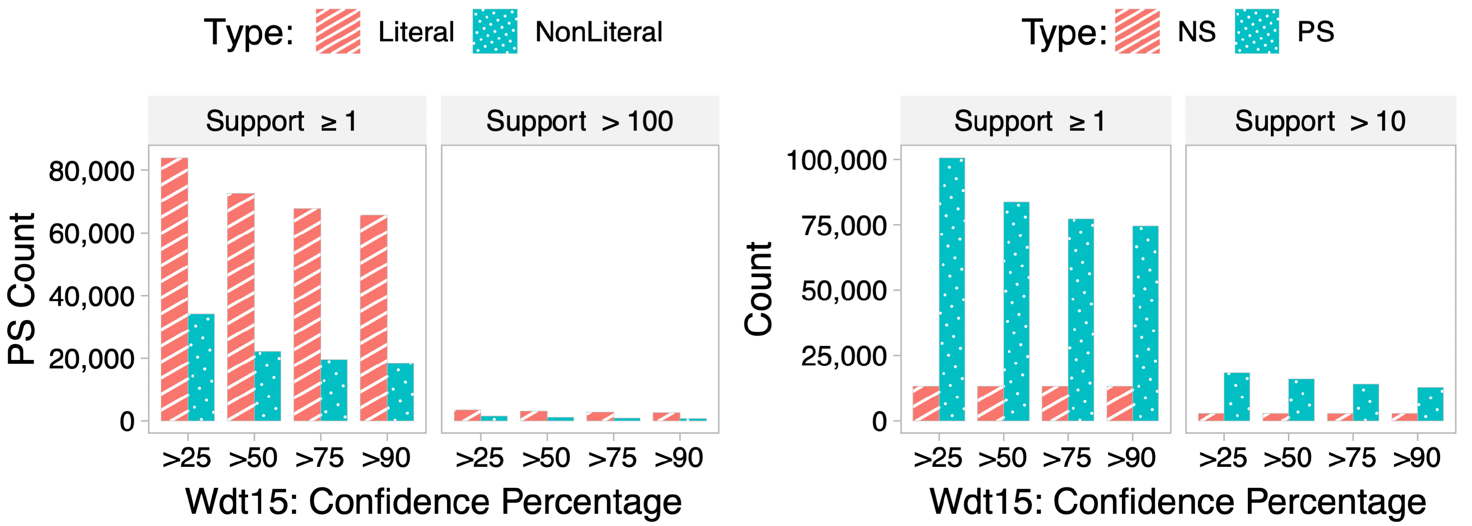
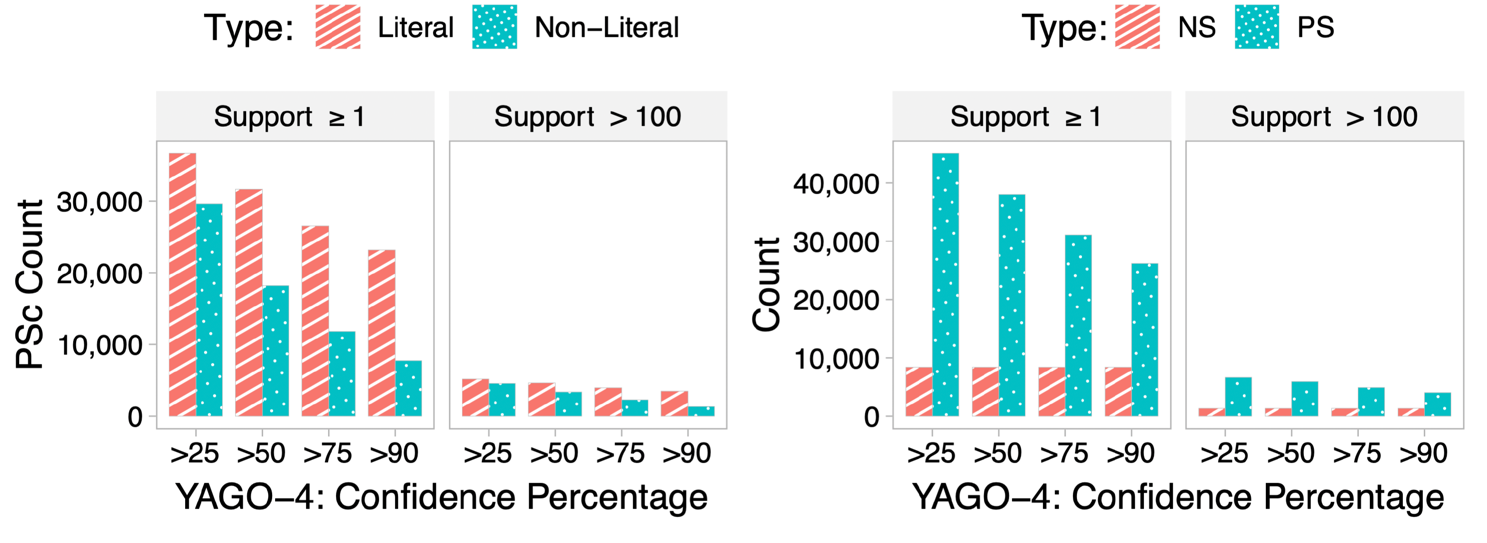
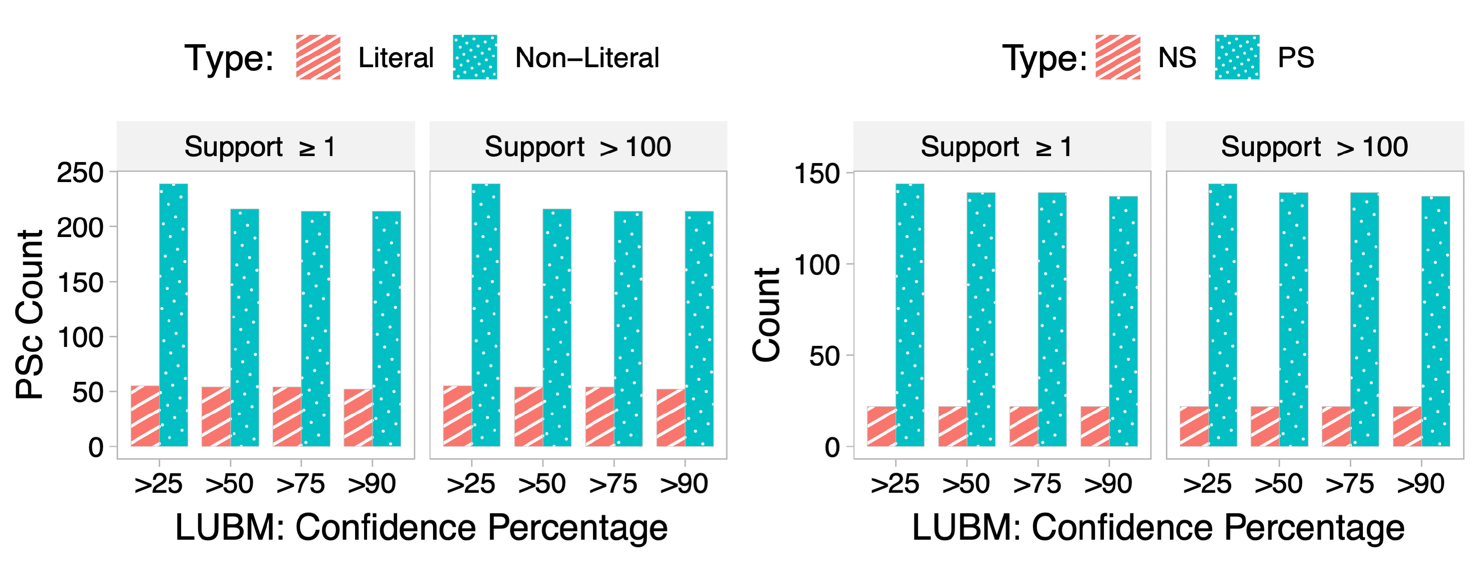
We have published the extracted SHACL shapes of all three datasets on Zenodo.
Additionally, we have also made available an executable Jar file of our application on Zenodo to extract
SHACL shapes from RDF datasets in .nt format.
Visit our GitHub repository.